1. Introduction to Exceptions
AnException is an object delivered by the Exception class. This Exception class is exposed by the System.Exception namespace. Exceptions are used to avoid system failure in an unexpected manner. Exception handles the failure situation that may arise. All the exceptions in the .NET Framework are derived from the System.Exception class. To understand
exception, we need to know two basic things:- Somebody sees a failure situation that happened and throws an exception by packing the valid information.
- Somebody who knows that a failure may happen catches the exception thrown. We call it
ExceptionHandler.
Exception is not handled: class ExceptionsEx
{
//001: Start the Program Execution.
public void StartProgram()
{
Console.WriteLine("Making Call to F1() " );
F1();
Console.WriteLine("Successfully returned from F1() " );
}
//002: Set of Function that calls each other
public void F1()
{
Console.WriteLine("Making Call to F2() " );
throw new System.Exception();
F2();
Console.WriteLine("Successfully returned from F2() " );
}
public void F2()
{
Console.WriteLine("Inside F2 " );
}
//Client 001: Program Entry
[STAThread]
static void Main(string[] args)
{
//Create the Object and start the Execution
ExceptionsEx app = new ExceptionsEx();
app.StartProgram();
}
}
In the above code, look at the function F1 that throws an Exception. But, there is no handler to deal with the thrown exception. This situation is called an Un-Handled exception situation. When you execute the code, you get an unhandled exception dialog. 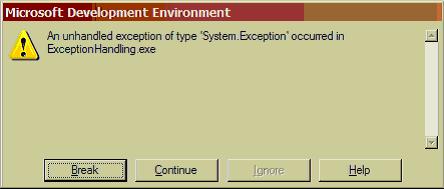 The above dialog is shown in debug mode, so you may get a chance to
break the execution to see where the exception is thrown (or) continue
ignoring the
The above dialog is shown in debug mode, so you may get a chance to
break the execution to see where the exception is thrown (or) continue
ignoring the exception (not advisable). In release mode, you will get un-handled
Exception in the form of Application crash. 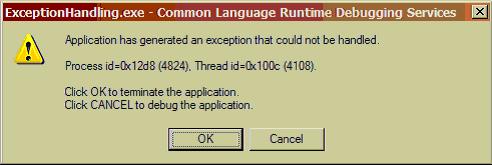 So, how do we avoid Un-Handled
So, how do we avoid Un-Handled Exception? Simple, handle it. 2. Handling Exception
To handle the exception, we need to place the code within thetry block. When an exception occurs inside the try block, the control looks for the catch block and raises an exception that is handled in the catch block. Below is the simple skeleton for the try and catch block: try
{
//Some Code that may expected to raise an exception
}
catch
{
//Raised exception Handled here
}
The above skeleton handles any exception. But, the main disadvantage is that we don’t know what exception is raised and who raised the exception. Below is the example that handles the Exception raised by the function F1 and avoids the crash: class ExceptionsEx
{
//001: Start the Program Execution.
public void StartProgram()
{
Console.WriteLine("Making Call to F1() " );
try
{
F1();
}
catch
{
Console.WriteLine("Some Exception Occurred.
I don't know what Exception it is and where it Occurred. Sorry!");
}
Console.WriteLine("Successfully returned from F1() " );
}
//002: Set of Function that calls each other
public void F1()
{
Console.WriteLine("Making Call to F2() " );
throw new System.Exception();
Console.WriteLine("Successfully returned from F2() " );
}
//Client 001: Program Entry
[STAThread]
static void Main(string[] args)
{
//Create the Object and start the Execution
ExceptionsEx app = new ExceptionsEx();
app.StartProgram();
}
}
3. Exception Bubbling
In the above example, we saw thatException is handled in the catch block. But, the function call order is simple (Call Stack) that is; StartProgram calls the function F1 and F1 raised exception is handled in the catch block of the StartProgram. Imagine the situation what happens if there are multiple nested function calls, and
exception occurred in the fourth or fifth nested call. Look at the picture below: 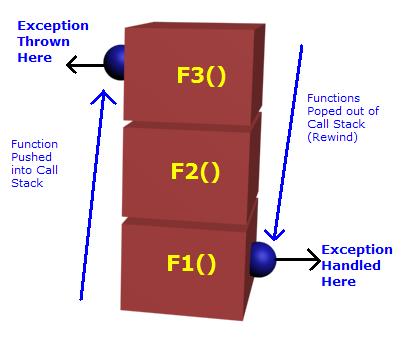
F1(): CallsF2within thetryblock and handles the exception incatchblockF2(): Makes a call to the functionF3. But it neither wraps the call forF3in thetryblock nor has the exception handlerF3(): Raises an Exception
F3, even though the caller is F2, as there is no catch handler, the execution comes out of F2 and enters the catch block of F1. Travelling back from F3->F2->F1 is known as Stack Unwind. And exception occurred in F3 is handled in F1 even when there is no handler at F2 is known as Exception Bubbling.Below is the example that demonstrates the
Exception Bubbling: using System;
namespace ExceptionHandling
{
class ExceptionsEx
{
//001: Start the Program Execution.
public void StartProgram()
{
Console.WriteLine("Making Call to F1() " );
try
{
F1();
}
catch
{
Console.WriteLine("Some Exception Occurred.
I don't know what Exception it is and where it Occurred. Sorry!");
}
Console.WriteLine("Successfully returned from F1() " );
}
//002: Set of Function that calls each other
public void F1()
{
Console.WriteLine("Making Call to F2() " );
F2();
Console.WriteLine("Successfully returned from F2() " );
}
public void F2()
{
Console.WriteLine("Making Call to F2() " );
F3();
Console.WriteLine("Successfully returned from F2() " );
}
public void F3()
{
Console.WriteLine("Inside F3 " );
throw new System.Exception();
}
//Client 001: Program Entry
[STAThread]
static void Main(string[] args)
{
//Create the Object and start the Execution
ExceptionsEx app = new ExceptionsEx();
app.StartProgram();
}
}
}
4. The Importance of Finally Block
In the above example, we saw that when anexception occurs, we directly jump back on the call stack and travel back searching for the catch
handler. What about the piece of code that comes next to the exception
raising code? If we do releasing resource and releasing the heap memory
in the next couple of statements, that will not get reached. Right? Finally block is the solution for this. Now look at the improved exception-handling skeleton below:try
{
}
catch
{
}
finally
{
}
Whatever happens inside the try block, it is guaranteed that finally block gets executed. Hence, all resource releases should be in the finally block. Have a look at the below picture: 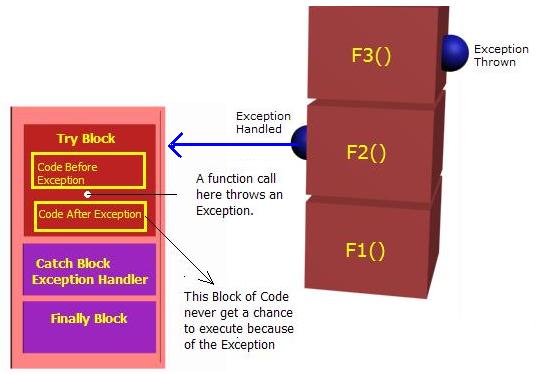
Exception raised at function F3 is handled in the function F2. Look at the try block, I marked two blocks of code before exception and code after exception. It is obvious that when an exception
raised, the set of code inside the code after exception is never
executed. If resources are allocated in code before exception and the
allocated resources are released in code after exception, we do have a
resource leak for each exception occurred. Also, think about business logic that needs to revert back apart from the resource leak. This is why finally block is introduced. Whether an
Exception occurs or not, the code inside finally block always gets executed. So you can keep all the cleaning code inside the finally
block. The attached sample solution explains the above situation. Put a
break point in the very first statement of the function public void StartProgram() and examine the situation explained above. Note, the usage of try block with only finally and without catch in function F2. Think about it.5. What is Exception Class?
This class is provided by .NET Framework to handle anyexception that occurred. The Exception class is the base class for all other Exception class provided by .NET Framework.The exception object has some important properties. Some of then are given below:
| Property | Usage |
Message |
Gives detailed information about the message |
StackTrace |
Gives the function stack to show where exception is thrown |
Targetsite |
Shows which method throws the exception |
catch block and missed all the above said information. The exception object is thrown by the piece of code, which raises an Exception and the handler code catches that Exception object and makes use of the information packed in it. Consider the below example:void SomefunctionX()
{
throw new DivideByZeroException();
}
void SomeFunctionY()
{
try
{
SomefunctionX();
}
catch (DivideByZeroException Ex)
{
//Use the Ex here to get information
}
}
The example was shown just to understand from where the object that is used in the catch block is coming from. Hope, now you know the exception instance created on the throw statement caught in the catch block and used. Note that, the base class of DivideByZeroException is ArithmaticException, which is derived from the System.Exception. Now the question is, May I use ArithmaticException in the catch
block? Yes. Why not? That is the beauty of polymorphism. When you do,
always keep in mind that you are moving from more specialized
information thrown to the generalized one.6. Handler for Multiple Exceptions
A code placed in thetry block can raise different kinds
of exception. It can be say, a Divide by Zero or a Network System
Access Denied or a File not exists. How do you handle all the
exceptions? The answer is, you can place multiple catch blocks for a try block. When an exception is thrown, type of that exception is examined against each catch block. When a match occurs (even polymorph), the exception enters into the catch block and gets handled. Let me walk through an example, which will explain the following to you:
- Make use of
Exceptionobject in thecatchblock - Using multiple
catchblocks for differentexceptions - The importance order of the
catchblocks
StartProgram after creating the object of type ExceptionsP2. [STAThread]
public static void Main(string[] args)
{
ExceptionsP2 start = new ExceptionsP2();
start.StartProgram();
}
2) The StartProgram function makes a call to Calculate function. And this call is placed in the try block as it is expected that there be some arithmetic exception and possibly a Divide by Zero exception. Two catch blocks are placed for the try block of code. One is DivideByZeroException and other one is System.Exception. Inside each catch block, the exception object caught was used to display the Exception message, and function call stack of where the exception raised. Below is the code://001: Function that Handles the Exception
public void StartProgram()
{
Console.WriteLine("Calling the Function Calculate");
try
{
Calculate();
}
catch (DivideByZeroException Ex)
{
Console.WriteLine("Divide By Zero.
Look at the Call stack for More information");
Console.WriteLine("Packed Message: " + Ex.Message );
Console.WriteLine("Thrown By: " + Ex.TargetSite );
Console.Write("Call Stack: " + Ex.StackTrace );
}
catch (Exception Ex)
{
Console.WriteLine("General Exception Occurred");
Console.WriteLine("Packed Message: " + Ex.Message );
Console.Write("Call Stack: " + Ex.StackTrace );
}
}
3) The calculate is just an intermediate function which makes a call to Divide.
Note how the stack rewind and exception bubbling is happening. Below is
the function which makes a call to divide, and does not have any
Exception handler code://002: An intermediate function, just for Demo Purpose
public void Calculate()
{
Console.WriteLine("Calling Divide Function ");
Divide();
}
4) The divide function tries to divide a number by zero.
The .NET environment detects the situation and raises the exception for
us. Note there is no throw statement here. In my previous examples (actually in the previous part), I forced the system to throw an Exception for my demonstration purpose. We usually use the throw
statement for Custom defined exceptions. The .NET environment is smart
enough to detect the exception at right time and raise it. Below is the
code for divide: //003: The Divide function which actually raises an Exception
public void Divide()
{
int x = 10;
int y = 0;
y = x / y;
}
7. Closing Notes
TheDivideByZeroException thrown in the Divide function is caught by the StartProgram function. Then the exception object is matched against the first catch block. As there is a match, the exception enters that catch block.What happens if
System.Exception catch block is before the DivideByZeroException? We do enter the System.Exception catch block even though a more perfect match exists. Because, the exception caught is matched from top to bottom. As the System.Exception is on the top (that is; Before DivideByZero) and the caught Exception DivideByZeroException is polymorphically a System.Exception the execution control just enters the System.Exception catch block.So always keep in mind to place more specific
catch statement first and move down with more Generalized Exceptions. Look at the code below how a smart developer placed his catch block based on what his Team Lead told. Lead: “The code block may raise a
DivideByZeroException or Any ArithmeticException. It is possible to have FileNotFound Exception also. These are the possibilities of Exception I am seeing when I am reviewing your code. But, for safety, try to handle all exceptions in the world and it is OK if it is not more specific”. That's all, the Lead went to a meeting.
Forget what meeting he is going for, see how the developer placed his
catch block:try
{
// The set of code and function here
// reviewed by an Experienced lead.
}
catch (System.FileNotFoundException Ex)
{
//File Not Found Exception is Different from Divide by zero.
//Look at the Inheritance hierarchy in MSDN for FileNotFoundException
//and DivideByZeroException.
//So I don't care Which one First, FileNotFond or DivideByZero
}
catch( System.DivideByZeroException Ex)
{
//Divide by Zero Exception. Need More Specialized care
}
catch (System.ArithmeticException Ex)
{
// For any ArithmaticException except DivideByZero. Because I already handled it
// before this catch statement
}
catch(System.Exception Ex)
{
//I am not expecting that this would Occur. As per my Lead
//I placed it for safe to handle any Exception in the world
// That derived from Exception.
}
finally
{
//Clean-up code
}